728x90
| Introduction to Word Embedding |
| 1. Word Representation |
| 2. Using word embeddings |
| 3. Properties of word embeddings |
| 4. Embedding Matrix |
1. Word Representation

- 위는 기존 one-hot 벡터방식의 단어표현인데, 다음과 같은 문제점이 있다.
- one-hot 벡터 방식에서는 apple과 orange의 관계가 apple과 king의 관계와 다르지 않다.
- 따라서 설령 우리가 i want a glass of orange juice 를 학습했다 하더라도, i want a glass of apple __ 에서 'juice' 라는 답을 찾을 수 없다.
- 즉, 단어간의 관계를 알 수가 없는 것.

- 그래서 featurized respresentation을 이용할 수 있다.
- 방식은 위와 같다. 해당 피쳐와의 관련도에 따라 점수를 매기는 것.
- e 옆의 숫자는 vocabulary 상에서 단어의 위치이다.
- 이를 통해 단어간의 관계를 표현할 수 있으며 'apple juice'를 예측할 수 있다.

- 이렇게 만든 300차원의 벡터들을 2차원으로 시각화하면 위와 같은 분포가 될 것이다
- 이를 통해 단어끼리 그룹화 할 수 있음.
- 2차원으로 바꾸는 알고리즘은 t-SNE 알고리즘을 이용함.
- 왜 word embedding이냐 ? 위와 같이 특정 단어를 n(피쳐개수)차원의 공간의 어느 부분에 묻어두기 때문.
2. Using word embeddings
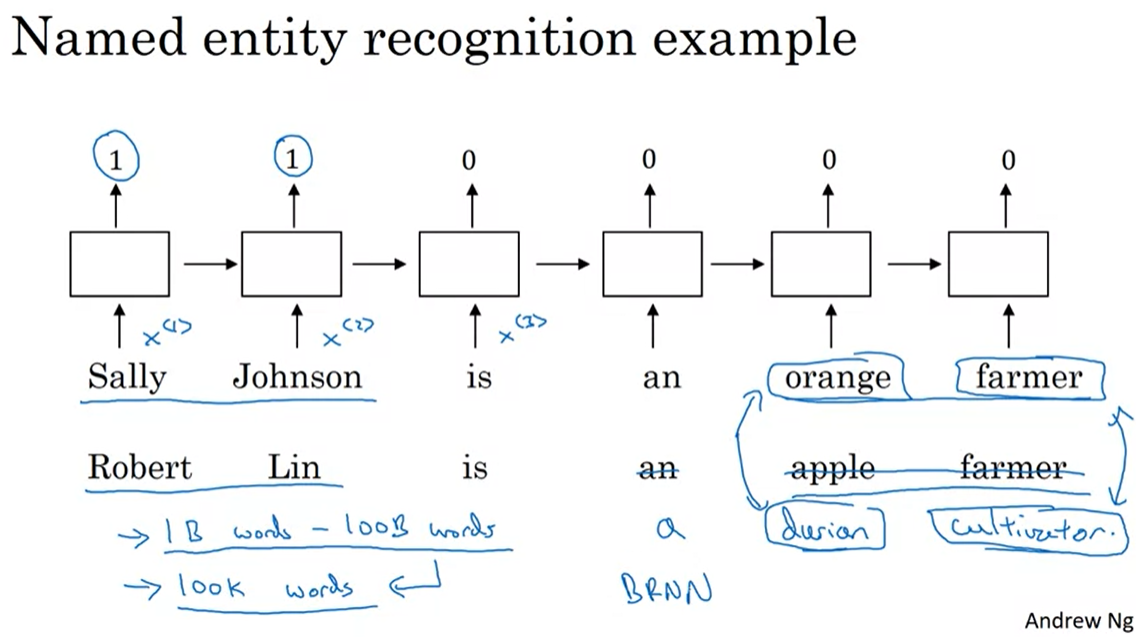
- sally johnson이 사람 이름인 것을 알려면 orange farmer가 사람인 것을 알아야 한다.
- 만약 word embedding으로 학습을 한다면 두번째 문장도 정답을 맞출 수 있다.
- 심지어 durian cultivator라는 단어가 대신 들어가도 이름을 식별할 수 있다. durian vultivator라는 특이한 단어의 경우, training set에서 보지 않았으므로 기존 원핫벡터 방식으로는 예측이 힘들지만 word embedding을 이용하면 예측이 가능하다.
- 이는 featured 방식으로 인해 orange farmer와 durian cultivator를 비슷한 그룹으로 인식하기 때문

- 이는 전이 학습(transfer learning)의 효과를 만들어 낸다.
- 수백만개의 unlabeled word를 word embedding 방식으로 학습함으로써 durian cultivator를 train시키지 않았음에도 test time에서 유용한 효과를 거둘 수 있음.
- 즉, named entity recognition을 수행할때 상대적으로 적은 train set으로도 괜찮은 성능을 낼 수 있다.
- 구체적인 절차는 위와 같으며, transfer할 때 기존 원핫벡터와는 다르게 적은 차원으로 training set을 구성가능하며 자연스레 training set은 dense vector일 것이다(one-hot 벡터는 sparse vector).
- 그리고 새로운 train data의 수에 따라 large text corpus로부터 학습한 word embedding을 조금씩 수정할 수도 있다. 이건 예전에 transfer 할때 했던거 그대로 적용되는 개념이다.
- 참고로 전이학습의 특성상, a task의 데이터 수가 많고 b task의 데이터 수가 적을 때 효과가 큰데, language modelling 이나 machine translation 분야에서는 효과가 떨어진다.

- face recognition에서 encoding과 word embedding에서 embedding의 개념은 비슷한데, 한가지 차이점은 전자의 모델은 CNN의 네트워크를 학습하고자 한 것이고, 후자의 경우는 vocabulary의 word vector 자체를 학습하고자 하는 것.
- 전자는 어떠한 input image라도 올 수 있으며, 후자의 경우는 고정된 vocabulary가 있기 때문.
- 정확히 말하면 encoding 과 embedding의 차이라기보다는 두 알고리즘의 차이이다.
Face recognition에서 encoding의 개념을 설명한 아주 좋은 글을 소개한다.
jackiechansbigdata.tistory.com/26?category=941594
[Week 4] 1. Face recognition
Face recognition 1. What is face recognition? 2. One Shot Learning 3. Slamese Network 4. Triplet Loss 5. Face Vertification and Binary Classification 1. What is face recognition? - Verification : I..
jackiechansbigdata.tistory.com
3. Properties of word embeddings

- word embedding은 유추문제에도 적용할 수 있는데, 이것이 NLP와 관련된 문제는 아닐지라도 word embedding을 이해하는데 도움이 된다.
- 다음과 같은 유추문제가 있다고 생각해보자.
(Man -> wowan as King -> ____ ?)
if Man is woman then king is what? - 빈칸에 들어갈 적절한 단어는 queen일 것이다.
- 이러한 유추문제에 대한 답을 찾기 위해 우리가 정의한 word vector들에서 e_man - e_woman을 해보자.
- 이 결과는 e_king - e_queen의 결과와 유사할 것이다. 두 벡터들의 차이는 성별하나이기 때문이다.
- 다시 문제로 돌아가서 빈칸을 맞추기 위한 과정은
e_man-e_woman의 결과와 e_king - e_? 의 결과를 비슷하게 하는 e_? 를 찾는 과정과 같아진다.

- 공식화해보자.
- 그림으로 표현하면 위와 같다. 화살표는 두 단어벡터간의 차이라고 할 수 있다.
- e_?를 e_w라고 하면 word w를 찾는 과정은 위 두 벡터의 유사도를 최대로 하는 w를 찾는 것이다.
- 위에서 e_w를 좌변으로 넘기고 나머지를 우변으로 넘긴 후 유사도 비교하는 것.
- word embedding을 통한 유추문제 해결은 꽤나 좋은 성능을 보여준다.
- 참고로 t_SNE 방식으로 차원축소를 했으므로 왼쪽 그림과 같이 두 쌍의 단어간의 관계가 평행사변형 모양으로 나오지는 않는다.
- 왼쪽의 평면은 평면으로 표현되었지만 사실 300차원의 공간이다.
- t_SNE 방식은 비선형적인 방법으로 차원을 축소했고, 우리는 두 쌍의 벡터간의 차이가 일정하다는 전제하에 공식을 만들었기 때문에 t_SNE를 적용하고 나서는 좀 전에 얘기했던 방식으로 word w 를 찾을 수 없다.

- 자주 쓰는건 코사인 유사도이다. sim(u, v)는 두 벡터의 각도에 대한 코사인값인데, 각도가 작을 수록 코사인 값은 1에 가까워져 유사도가 커지며 각도가 클수록 유사도가 작아진다. 자세한건 구글링을 해보면 된다.
- 그 외에도 유클리드 거리를 사용할 수도 있다.
4. Embedding Matrix

- 그래서 우린 뭘해야하느냐~
- 이전까지 딥러닝 모델에서 weight들을 학습했던 것과는 다르게 우리는 featured word vector들의 집합인 Embedding Matrix를 학습해야 한다.
- 왼쪽이 Embedding Matrix이고 오른쪽은 특정 word의 one-hot vector이다.
- 둘을 행렬곱해주면 자연스레 특정 word의 300차원짜리 벡터(e_j = embedding for word j)가 나온다.
- 우리는 이 벡터의 element들을 randomly initialization하여 경사하강법으로 업데이트할 것이다.
- 참고로 편의상 위와 같이 행렬곱으로 표현하였으나, one-hot 벡터의 특성상 대부분 0으로 구성되어 있고 이를 행렬연산해주는 것은 비효율적이다.
- 따라서 실제로 적용할 때에는 Matrix E에서 특정 컬럼을 추출하는 방식으로 word vector를 가져온다고 하는데, 자세한건 뒤에 알려줄 거같다.
비판과 질문은 언제나 환영입니다. 많이 꾸짖어주세요.
728x90
'DeepLearning Specialization(Andrew Ng) > Sequence Models' 카테고리의 다른 글
| [코세라] [Week 2] Quiz & Programming Assignments (0) | 2020.12.20 |
|---|---|
| [코세라] [Week 2_NLP & Word Embedding] 3. Applications Using Word Embeddings (0) | 2020.12.19 |
| [코세라] [Week 2] 2. Learning word embeddings : Word2vec & GloVe (0) | 2020.12.19 |
| [Week 1] Quiz & Programming Assignments (0) | 2020.12.14 |
| [코세라] [Week 1] 1. Recurrent Neural Networks (0) | 2020.12.05 |



