# Quiz
# Programming Assignments
1st Assignments : Neural Machine Translation with Attention

1. previous timestep's prediction as input
- Unlike previous text generation examples earlier in the course, in this model, the post-attention LSTM at time tt does not take the previous time step's prediction y⟨t−1⟩y⟨t−1⟩ as input.
- The post-attention LSTM at time 't' only takes the hidden state s⟨t⟩s⟨t⟩ and cell state c⟨t⟩c⟨t⟩ as input.
- We have designed the model this way because unlike language generation (where adjacent characters are highly correlated) there isn't as strong a dependency between the previous character and the next character in a YYYY-MM-DD date.
강의에서 기계번역을 할 때, Post LSTM(위쪽 RNN) 에서 지난 timestep에서의 예측값을 다음 timestep에 인풋으로 전달했었다. 그 이유는 기계번역과 같은 text generation에서는 단어간에 높은 상관성을 갖지만 과제에서처럼 날짜데이터의 경우 단어 간의 상관성이 없으며 따라서 고려할 필요도 없다. 그래서 previous prediction을 다음 타임스텝에 전달하지 않음.
2. 교사강요(Teach Forcing)
모델을 설계하기 전에 혹시 의아한 점은 없으신가요? 현재 시점의 디코더 셀의 입력은 오직 이전 디코더 셀의 출력을 입력으로 받는다고 설명하였는데 decoder_input이 왜 필요할까요?
훈련 과정에서는 이전 시점의 디코더 셀의 출력을 현재 시점의 디코더 셀의 입력으로 넣어주지 않고, 이전 시점의 실제값을 현재 시점의 디코더 셀의 입력값으로 하는 방법을 사용할 겁니다. 그 이유는 이전 시점의 디코더 셀의 예측이 틀렸는데 이를 현재 시점의 디코더 셀의 입력으로 사용하면 현재 시점의 디코더 셀의 예측도 잘못될 가능성이 높고 이는 연쇄 작용으로 디코더 전체의 예측을 어렵게 합니다. 이런 상황이 반복되면 훈련 시간이 느려집니다.
만약 이 상황을 원하지 않는다면 이전 시점의 디코더 셀의 예측값 대신 실제값을 현재 시점의 디코더 셀의 입력으로 사용하는 방법을 사용할 수 있습니다. 이와 같이 RNN의 모든 시점에 대해서 이전 시점의 예측값 대신 실제값을 입력으로 주는 방법을 교사 강요라고 합니다.
출처는 여기
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
3. RepeatVector()
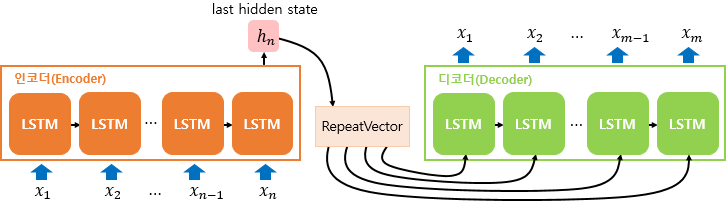
캡쳐1에서 s<t-1>과 a<t'>이 alpha 를 계산하기 위해 이용된다. 이 과정에서 s<t-1>을 여러번 반복적으로 NN에 input해야하는데 이 때 이용되는 것이 RepeatVector()이다. 사용되는 방법은 캡쳐3와 같으며 캡쳐3는 우리가 만드는 모형과는 무관하다.
2nd Assignments : Trigger word detection
1. 오디오 전처리
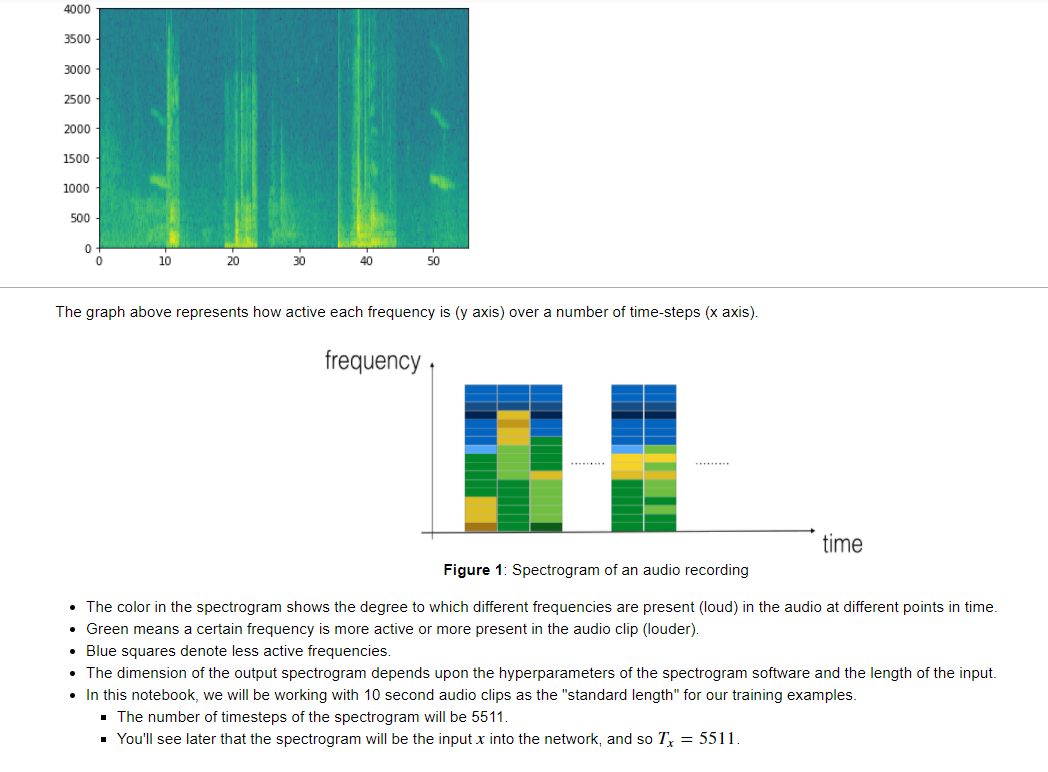
- 앞서 언급했듯이 Speech recognition을 할때에는 airpressure - time 데이터를 frequency - time 데이터로 바꾸어주어야한다. 위의 그래프는 전처리 후의 데이터이다.
- 해석하자면, 특정 시간에서 어떤 주파수(frequecny)가 어떤 강도(how active or present or loud)로 나타났는지에 따라 색이 칠해진 것이다.
- 초록색은 active 한 것. 파란색은 반대
- 오디오 데이터를 전처리하는 과정에서 기존 airpressure - time 데이터는 단지 441000 차원의 벡터로 표현할 수 있지만, spectorgram 데이터는 정보(how active)를 하나 더 포함하고 있으므로 2차원 array로 표현해야 한다.
2. Conv1D
- 오디오클립의 경우 input 데이터가 1-dimension이므로 conv1d 레이어를 사용한다.
# GRADED FUNCTION: model
def model(input_shape):
"""
Function creating the model's graph in Keras.
Argument:
input_shape -- shape of the model's input data (using Keras conventions)
Returns:
model -- Keras model instance
"""
X_input = Input(shape = input_shape)
### START CODE HERE ###
# Step 1: CONV layer (≈4 lines)
print(X_input.shape)
X = Conv1D(filters=196,kernel_size=15,strides=4)(X_input) # CONV1D
print(X.shape)
X = BatchNormalization()(X) # Batch normalization
X = Activation('relu')(X) # ReLu activation
X = Dropout(0.8)(X) # dropout (use 0.8)
# Step 2: First GRU Layer (≈4 lines)
X = GRU(units = 128, return_sequences = True)(X) # GRU (use 128 units and return the sequences)
X = Dropout(0.8)(X) # dropout (use 0.8)
X = BatchNormalization()(X) # Batch normalization
# Step 3: Second GRU Layer (≈4 lines)
X = GRU(units = 128, return_sequences = True)(X) # GRU (use 128 units and return the sequences)
X = Dropout(0.8)(X) # dropout (use 0.8)
X = BatchNormalization()(X) # Batch normalization
X = Dropout(0.8)(X) # dropout (use 0.8)
# Step 4: Time-distributed dense layer (see given code in instructions) (≈1 line)
X = TimeDistributed(Dense(1, activation = "sigmoid"))(X) # time distributed (sigmoid)
### END CODE HERE ###
model = Model(inputs = X_input, outputs = X)
return model - Conv1d에 대한 이해가 부족한 거 같아서 구글링을 좀 해보았다.
- 우리가 과제에서 다루는 데이터는 (Tx, n_freq)의 형태로서 예에전 CNN 에서 다룬 이미지 데이터와는 다르다.
- 이게 좀 헷갈릴 수 있는게, 이미지도 흑백이미지의 경우 2차원이고 conv2d를 적용했던 기억이 있을 것이다. 그러나 그것과는 근본적으로 다르다. 흑백이미지는 2차원 데이터처럼 보이지만 사실은 (Length, Width, Channel = 1)로 구성된 3차원 데이터이며 따라서 conv2d가 적용된다.
- 반면 오디오 데이터는 (timestep, feature dimension) 으로 구성된 2차원 데이터이고 feature dimension이 channel 의 역할을 한다.
- 따라서 만약 filter size 가 5라면 (5, feature dimension) 모양의 filter와 연산을 하게 되는 것이다. 마치 channel처럼
딱 원하는 점을 적어놓은 블로그다.
[PyTorch] 시계열 데이터를 위한 1D convolution과 1x1 convolution
오늘은 시계열 데이터처리에 많이 사용되는 1D convolution이 PyTorch에 어떻게 구현되어 있는지와 어떤 파라미터가 존재하는지 차원은 어떻게 계산하는 지를 정리해 보려고 한다. 자꾸 까먹는 나 자
sanghyu.tistory.com
3. Timedistributed() layer
- 요거에 대한 확실한 직관을 얻을 수 없어 몇몇 글들을 읽었다.
- 생각보다 별게 없다.
- 요약하자면 다음과 같다.
LSTM 알고리즘을 사용하는데 (units = 5, return_sequences = True) 라 하자.
그러면 매 timestep 마다
machinelearningmastery.com/timedistributed-layer-for-long-short-term-memory-networks-in-python/
How to Use the TimeDistributed Layer in Keras
Long Short-Term Networks or LSTMs are a popular and powerful type of Recurrent Neural Network, or RNN. They can be quite difficult to configure and apply to arbitrary sequence prediction problems, even with well defined and “easy to use” interfaces lik
machinelearningmastery.com
2. Keras LSTM 유형 정리 (2/5) – 단층-단방향 & many-to-many 유형
1. 단층-단방향 & many-to-one 유형 2. 단층-단방향 & many-to-many 유형 3. 단층-양방향 & ma...
blog.naver.com
4. RNN 의 units parameter
- LSTM이든 GRU 던 그냥 simple RNN이든 Keras layer를 설정할 때, parameter로 units를 설정한다. 이게 정확히 무슨 의미일까? activation은 그냥 timestep별로 하나인게 아닌가? 라는 생각이 들었다.
- 이에 대한 답은, a<t> 는 하나의 hidden cell이고 그 cell을 구성하는 것이 unit이다.
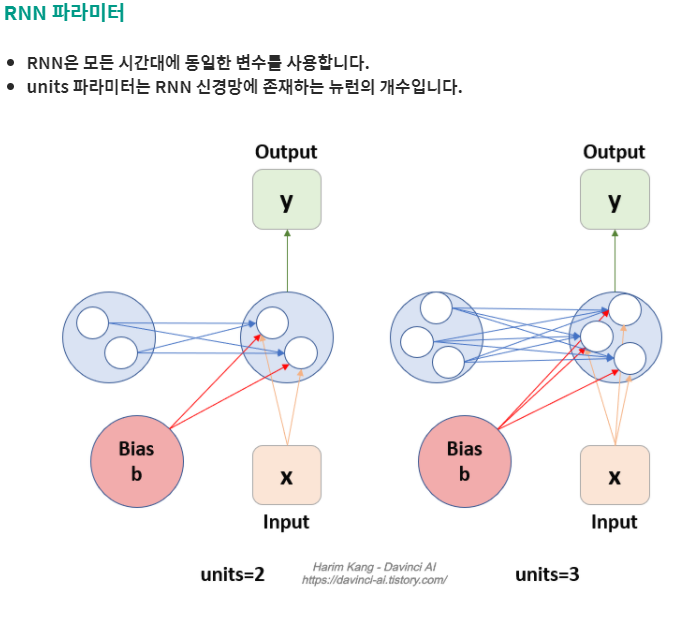
- 따라서 activation a 의 matrix와 관련된 Weight 들도 그에 맞게 차원이 변경된다.
비판과 질문은 언제나 환영입니다. 많이 꾸짖어주세요.



